
C언어의 포인터 이야기
□ C언어 포인터 개념 I
■ C언어 포인터 개념 II - float,double,char, string 포인터
□ C언어 포인터 개념 III - struct 포인터 & void 포인터
□ C언어 포인터 개념 III - struct - C++ 포인터 Linked-List
□ C언어 포인터 개념 III - struct 포인터 2
지금 까지는 정수형 변수의 포인터 개념을 보았다. 모든 포인터는 데이터를 위치를 지정하는 변수 이므로 메모리의 주소값으로 처리 한다고 언급 했다.
실수형 변수의 포인터
프로그램에서 정수형에 비해 실수형은 그리 많이 사용하지는 않는다. 숫자의 표현이나 길이의 차이는 있지만 포인터를 처리하는 방식은 그리 다리지 않다.
실수형을 좀 더 자세히 알고 싶다면
http://blog.naver.com/dolicom/10319105
우선
sizeof(float) = 4
sizeof(double) = 8
그러면 포인터의 길이는
sizeof(float*) = sizeof(double*) = sizeof(char*) = sizeof(int*) = sizeof(void*) = sizeof(struct xxx *) = ...
이것은 CPU와 메모리의 구조에서 이미 얻급한 내용이다. CPU마다 메모리를 처리하는 것은 결정 되어 있고 이것에 맞추어 메모리를 설계하는 것이므로 CPU마다 다르다.
32비트 CPU : sizeof(float*) = sizeof(double*) = 4
실수 역시 주소값과 고정 실수(숫자)는 int의 예 처럼 코드 다음에 온다.
float cPi; ---> 0x0040DF04에 할당
float *pPi; ---> 0x0040DF00에 할당
pPi = &cPi;
*pPi = 3.141592f;
int 처럼
0401030 c7 05 00 DF 40 00 04 DF 40 00 mov DWORD PTR _pPi, OFFSET _cPi
이것은 메모리의 위치를 저장하는 것이므로 코드 상 int나 기타와 전혀 다른 것이 없다.
그렇다면 *pPi = 3.141592f;
은 어떨까?
이것을 분석을 다음과 같은 프로그램을 작성해 보았다.
float cPi;
float *pPi;
double dfp;
double *pdfp;
float fun()
{
pPi = &cPi;
. . .
*pPi = 3.141592f;
return *pPi;
}
void printvar()
{
printf("&cPi = 0x%08X\n", &cPi );
printf("&pPi = 0x%08X\n", &pPi );
printf("pPi = 0x%08X\n", pPi );
printf("*pPi = %f\n", *pPi );
printf("*((unsigned int*)pPi) = 0x%X\n", *((unsigned int*)pPi) );
printf("cPi = %f\n", cPi );
}
실행 결과 :
&cPi = 0x00403374
&pPi = 0x00403378
pPi = 0x00403374
*pPi = 3.141592
*((unsigned int*)pPi) = 0x40490FD8
cPi = 3.141592
이것을 생각하기 전에, 우선 float와 double의 상수값을 어떻게 취급하는지 본다.
정 수의 경우는 기계어 코드 다음에 오는 operand에 붙어 있다. 그러나 float는 32비트라서 레지스터에 숫자를 담을 수 있지만 double은 64비트라서 32비트 CPU는 하나의 레지스터에 담을 수 없다. 따라서 CPU의 상황에 따라 숫자 취급 방식은 다양하다. 그래서 우리가 흔히 사용하는 PC의 intel x386 VisualC++ 로 상황을 파악해 본다.
float cPi;
cPi = 3.141592f;
어셈블리로 컴파일 하면
PUBLIC __real@40490fd8
; COMDAT __real@40490fd8
CONST SEGMENT
__real@40490fd8 DD 040490fd8r ; 3.14159 => 0x40490fd8 이다
; Function compile flags: /Ogtpy
CONST ENDS
_TEXT SEGMENT
_fun PROC ; fun, COMDAT
00000 d9 0500 00 00 00 fld DWORD PTR __real@40490fd8
00010 d9 1d 00 00 00 00 fstp DWORD PTR _cPi ; cPi
_fun ENDP ; fun
_TEXT ENDS
여기서 CONST 세그먼트는 고정된 상수 변수들을 모아 돈 영역이다. 다른 예로는
printf("Hello");
여기서의 Hello 스트링도 이 CONST 세그먼트에 속한다.
CONST에 float나 double의 상수 값을 위치 시키고 여기에서 데이터를 float-point 처리 버퍼로 옮겨 놓고 처리 한다.
참 고 할 것은 x386의 ALU에서 float/double을 처리하지 못하고, FPU(coprocessor-Float-Point Unit) 모듈에서 처리 한다. FPU에서 모든 float-point 처리 ALU하는 하드웨어 구조가 있는 것이다. FPU에서 처리를 하려면 우선은 float-point 버퍼에 load하고 계산을 한 다음 다시 메모리로 옮긴다. 따라서 fld/fstp는 메모리에서 folat-point 버퍼로 그리고 반대로 데이터를 옮기는 명령이다.double이라면double dfp ; dfp = 3.14159265358;
; COMDAT __real@400921fb5443d6f4
CONST SEGMENT
__real@400921fb5443d6f4 DQ 0400921fb5443d6f4r ; 3.14159_TEXT SEGMENT
00049 dd 0500 00 00 00 fld QWORD PTR __real@400921fb5443d6f4
00059 dd 1d00 00 00 00 fstp QWORD PTR _dfp ; dfp
그러면 포인터 입장에서 분석해 본다.
정수형과 비교해 보면
*pa =10;
정수 10은 코드 뒤에 있는 것이 메모리로 옮겨 지고
float나 double은
; *pdfp = 3.14159265358;
0003b a100 00 00 00 mov eax, DWORD PTR _pdfp ; pdfp ---> EAX레지스터에 pdfp의 포인터 주속값을 옮긴다.
00040 dd 0500 00 00 00 fld QWORD PTR ___real@400921fb5443d6f4->그리고 float-point 처리 버퍼로 상수값 3.14...을 옮긴다.
00046 dd 18 fstp QWORD PTR [eax] ---> float-point 버퍼의 값을 다시 메모리로 옮긴다.
여기서 생각 할 것은 포인터 라는 것은 다른 데이터 타입과 같이 메모리의 주소값을 코드의 opreand난 레지스터의 direct address mode로 전송하는 과정이 포인터를 처리하는 방식이다.
double dfp;
double *pdfp;
void fun()
{
pdfp = &dfp;
*pdfp = 3.14159265358979323846;
}
void printdouble()
{
printf("&dfp = 0x%08X\n", &dfp );
printf("&pdfp = 0x%08X\n", &pdfp );
printf("pdfp = 0x%08X\n", pdfp );
printf("*pdfp = %1.20lg\n", *pdfp );
printf("*pdfp(hex) = 0x%08X%08X\n", *((unsigned int*)pdfp), *(((unsigned int*)pdfp)+1) );
printf("dfp = %1.20lg\n", dfp );
}
실행 결과 :
&dfp = 0x00403388
&pdfp = 0x00403378
pdfp = 0x00403388
*pdfp = 3.1415926535897931
*pdfp(hex) = 0x54442D18 400921FB : 3.14159265358979323846은 컴파일러에 의해 상수값 0x400921FB54442D18로 바뀌어 취급
dfp = 3.1415926535897931
숫자
3.14159265358979323846 (개발자가 취급하는 숫자) == 0x400921FB54442D18 (컴파일러가 취급하는 숫자-프로그램에 넣은 숫자)

double 은 64비트 숫자 이지만 포인터가 위치를 지정할 때는 무조건 CPU의 주소체계에 의해 x386은 32비트 이다. 그리고 float/double은 32/64비트로 데이터를 움직여야 하기 때문에 x386은 FPU 명령에 의해 이루어 진다.
이번에는 포인터를 활용한 계산하는 방식은
volatile double dfp;
volatile double *pdfp;
void fun()
{
dfp = 3.14159265358979323846;
pdfp = &dfp;
*pdfp *= 180.;
*pdfp /= 2.;
}
; 16 : dfp = 3.14159265358979323846;
00000 dd 05 00 00 00 00 fld QWORD PTR __real@400921fb54442d18
; 17 : pdfp = &dfp;
00006 c7 05 00 00 00 00 00 00 00 00 mov DWORD PTR _pdfp, OFFSET _dfp; pdfp, dfp
00010 dd 1d 00 00 00 00 fstp QWORD PTR _dfp ; dfp
; 18 : *pdfp *= 180.;
00016 dd 05 00 00 00 00 fld QWORD PTR _dfp ; dfp
0001c a1 00 00 00 00 mov eax, DWORD PTR _pdfp ; pdfp
00021 dc 0d 00 00 00 00 fmul QWORD PTR __real@4066800000000000
00027 dd 18 fstp QWORD PTR [eax]
PC 의 x486 이상에서는 FPU가 한 칩내에 있기 때문에 이 명령을 사용하여 동작 한다. IDE(Visual Studio, ...) 툴에 따라 이 옵션을 변경할 수도 있을 것이다. 어째든 default로 컴파일 한다면 FPU를 사용한다.
그렇지만 ARM(ARM7,ARM9,... - Vector Float-Point Processor가 없는 ARM) 처럼 FPU가 없다면 이것은 float-point을 계산하는 함수로 처리 된다.
이번에는 array와 포인터의 관계를 본다.
double dfpData[100];
double *pdfp;
double fun()
{
int cnt;
double ddata;
dfpData[0] = 3.14159265358;
dfpData[1] = 1.0;
dfpData[2] = -100.;
pdfp = dfpData;
}
위 프로그램은 double의 어래이 변수의 예를 보여주는 것인데, 실행결과를 그림으로 표시하면
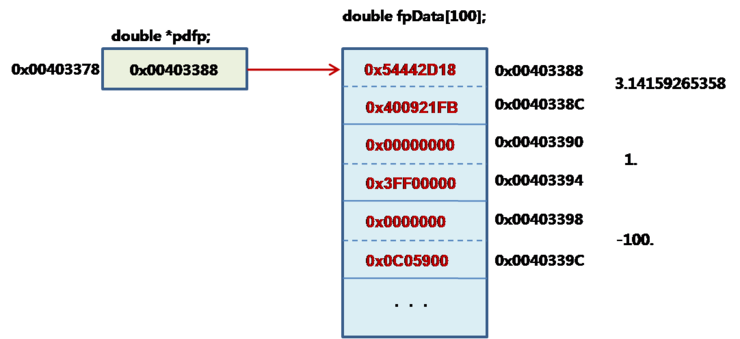
어래이의 값은
dfpData[0] = 3.14159265358;
dfpData[1] = 1.0;
dfpData[2] = -100.;
이것이 실행되면 어래이 100개 중에 3개의 값이 설정 된다.
참고로 double과 숫자와의 관계는

코드에서 우리가 흔히 사용하는 숫자를 사용하면 컴파일러가 double의 데이터 형태로 바꾼다.
여기서 pdfp가 어래이의 첫번째 주소값을 갖기 위해서는
pdfp = dfpData;
가 실행되면 이제서야 포인터가 위치를 지정 한다.
여기서
pdfp = dfpData;
pdfp = &dfpData[0];
2 줄이 같은 코드이다. C의 모든 포인터에서 변수의 앞 이름만을 사용하면 해당 변수의 초기 변수 위치를 지정 한다.
여기서 만약
pdfp++;
했다면 어떻게 될까?
이것은 모든 포인터의 기본 공식이다.
pdfp = pdfp + 1; => pdfp의 주소값+sizeof(double) = 0x00403388 + 8 = 0x00403390 == &dfpData[1]
다음 데이터가 있는 위치가 된다.
포인터의 증가는 데이터 위치의 증가 이므로 단순히 숫자 1을 더하는 것이 아니다.
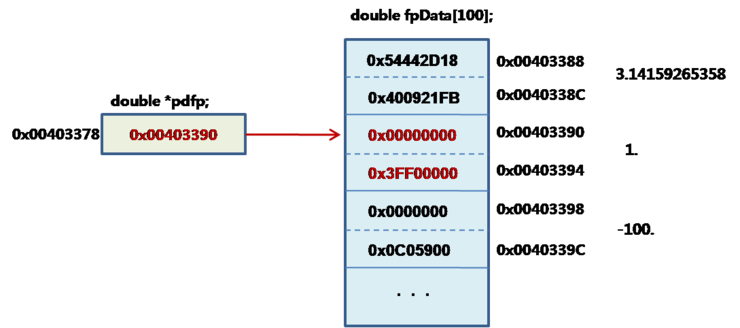
double 포인터 표현 몇가지
pdfp = dfpData;
double ddata = *(pdfp+2);
여기서
pdfp+2의 주소 계산은 같은 원리로 인덱스 2가 있는 위치가 된다.
pdfp의 주소값+sizeof(double)*2 = 0x00403388 + 16 = 0x00403398 == &dfpData[2]
와 같이 된다.
이것은 실제로
double ddata = dfpData[2];
와 같은 코드가 된다.
이것을 함수에서 표현을 보면
double sum1(double *pdata, int length)
{
int sum;
for (int cnt =0;cnt < length;cnt++)
sum += *(pdata+cnt);
return sum;
}
double sum2(double *pdata, int length)
{
int sum;
for (int cnt =0;cnt < length;cnt++)
sum += pdata[cnt];
return sum;
}
위의 두 함수 sum1과 sum2는 같은 코드이다.
double sum3(double *pdata, int length)
{
int sum;
for (int cnt =0;cnt < length;cnt++)
sum += *pdata++;
return sum;
}
sum3 만이 다른 포인터 계산 방식으로 코딩 된다.
String과 포인터
을 참고 하면 된다.

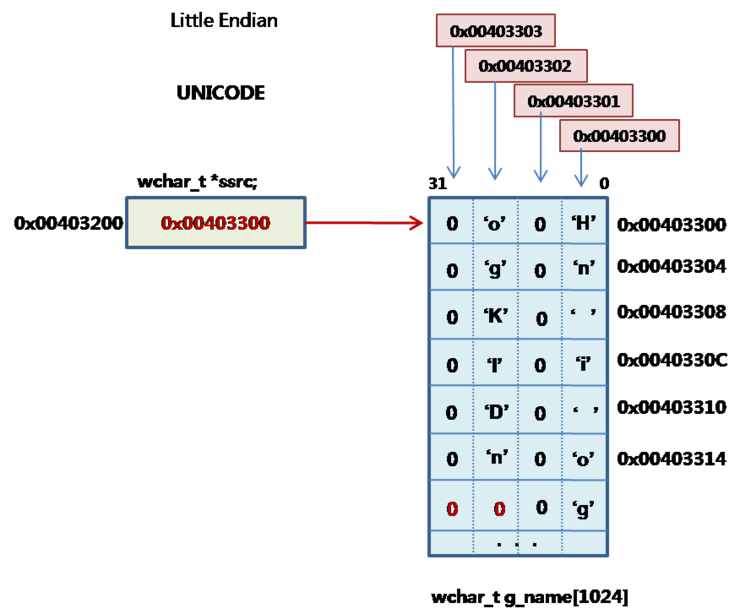
이 프로그램의 실행하기 위한 메모리 배치 구조가 위의 그림이다. wchar_t 사용 시, 만약 _UNICODE을 선언하지 않고 _MBCS가 선언되면 UNICODE가 만들어 지지 않는다. 이것은 결국 기존의 8비트 char로 처리 된다.
while (*ssrc)
*pstr++ = *ssrc++;
■ C언어 포인터 개념 II - float,double,char, string 포인터
□ C언어 포인터 개념 III - struct 포인터 & void 포인터
□ C언어 포인터 개념 III - struct - C++ 포인터 Linked-List
□ C언어 포인터 개념 III - struct 포인터 2
지금 까지는 정수형 변수의 포인터 개념을 보았다. 모든 포인터는 데이터를 위치를 지정하는 변수 이므로 메모리의 주소값으로 처리 한다고 언급 했다.
실수형 변수의 포인터
프로그램에서 정수형에 비해 실수형은 그리 많이 사용하지는 않는다. 숫자의 표현이나 길이의 차이는 있지만 포인터를 처리하는 방식은 그리 다리지 않다.
실수형을 좀 더 자세히 알고 싶다면
http://blog.naver.com/dolicom/10319105
우선
sizeof(float) = 4
sizeof(double) = 8
그러면 포인터의 길이는
sizeof(float*) = sizeof(double*) = sizeof(char*) = sizeof(int*) = sizeof(void*) = sizeof(struct xxx *) = ...
이것은 CPU와 메모리의 구조에서 이미 얻급한 내용이다. CPU마다 메모리를 처리하는 것은 결정 되어 있고 이것에 맞추어 메모리를 설계하는 것이므로 CPU마다 다르다.
32비트 CPU : sizeof(float*) = sizeof(double*) = 4
실수 역시 주소값과 고정 실수(숫자)는 int의 예 처럼 코드 다음에 온다.
float cPi; ---> 0x0040DF04에 할당
float *pPi; ---> 0x0040DF00에 할당
pPi = &cPi;
*pPi = 3.141592f;
int 처럼
0401030 c7 05 00 DF 40 00 04 DF 40 00 mov DWORD PTR _pPi, OFFSET _cPi
이것은 메모리의 위치를 저장하는 것이므로 코드 상 int나 기타와 전혀 다른 것이 없다.
그렇다면 *pPi = 3.141592f;
은 어떨까?
이것을 분석을 다음과 같은 프로그램을 작성해 보았다.
float cPi;
float *pPi;
double dfp;
double *pdfp;
float fun()
{
pPi = &cPi;
. . .
*pPi = 3.141592f;
return *pPi;
}
void printvar()
{
printf("&cPi = 0x%08X\n", &cPi );
printf("&pPi = 0x%08X\n", &pPi );
printf("pPi = 0x%08X\n", pPi );
printf("*pPi = %f\n", *pPi );
printf("*((unsigned int*)pPi) = 0x%X\n", *((unsigned int*)pPi) );
printf("cPi = %f\n", cPi );
}
실행 결과 :
&cPi = 0x00403374
&pPi = 0x00403378
pPi = 0x00403374
*pPi = 3.141592
*((unsigned int*)pPi) = 0x40490FD8
cPi = 3.141592
이것을 생각하기 전에, 우선 float와 double의 상수값을 어떻게 취급하는지 본다.
정 수의 경우는 기계어 코드 다음에 오는 operand에 붙어 있다. 그러나 float는 32비트라서 레지스터에 숫자를 담을 수 있지만 double은 64비트라서 32비트 CPU는 하나의 레지스터에 담을 수 없다. 따라서 CPU의 상황에 따라 숫자 취급 방식은 다양하다. 그래서 우리가 흔히 사용하는 PC의 intel x386 VisualC++ 로 상황을 파악해 본다.
float cPi;
cPi = 3.141592f;
어셈블리로 컴파일 하면
PUBLIC __real@40490fd8
; COMDAT __real@40490fd8
CONST SEGMENT
__real@40490fd8 DD 040490fd8r ; 3.14159 => 0x40490fd8 이다
; Function compile flags: /Ogtpy
CONST ENDS
_TEXT SEGMENT
_fun PROC ; fun, COMDAT
00000 d9 0500 00 00 00 fld DWORD PTR __real@40490fd8
00010 d9 1d 00 00 00 00 fstp DWORD PTR _cPi ; cPi
_fun ENDP ; fun
_TEXT ENDS
여기서 CONST 세그먼트는 고정된 상수 변수들을 모아 돈 영역이다. 다른 예로는
printf("Hello");
여기서의 Hello 스트링도 이 CONST 세그먼트에 속한다.
CONST에 float나 double의 상수 값을 위치 시키고 여기에서 데이터를 float-point 처리 버퍼로 옮겨 놓고 처리 한다.
참 고 할 것은 x386의 ALU에서 float/double을 처리하지 못하고, FPU(coprocessor-Float-Point Unit) 모듈에서 처리 한다. FPU에서 모든 float-point 처리 ALU하는 하드웨어 구조가 있는 것이다. FPU에서 처리를 하려면 우선은 float-point 버퍼에 load하고 계산을 한 다음 다시 메모리로 옮긴다. 따라서 fld/fstp는 메모리에서 folat-point 버퍼로 그리고 반대로 데이터를 옮기는 명령이다.double이라면double dfp ; dfp = 3.14159265358;
; COMDAT __real@400921fb5443d6f4
CONST SEGMENT
__real@400921fb5443d6f4 DQ 0400921fb5443d6f4r ; 3.14159_TEXT SEGMENT
00049 dd 0500 00 00 00 fld QWORD PTR __real@400921fb5443d6f4
00059 dd 1d00 00 00 00 fstp QWORD PTR _dfp ; dfp
그러면 포인터 입장에서 분석해 본다.
정수형과 비교해 보면
*pa =10;
0040103a c7 000A 00 00 00 mov DWORD PTR [eax], 10 ; 0000000aH
정수 10은 코드 뒤에 있는 것이 메모리로 옮겨 지고
float나 double은
; *pdfp = 3.14159265358;
0003b a100 00 00 00 mov eax, DWORD PTR _pdfp ; pdfp ---> EAX레지스터에 pdfp의 포인터 주속값을 옮긴다.
00040 dd 0500 00 00 00 fld QWORD PTR ___real@400921fb5443d6f4->그리고 float-point 처리 버퍼로 상수값 3.14...을 옮긴다.
00046 dd 18 fstp QWORD PTR [eax] ---> float-point 버퍼의 값을 다시 메모리로 옮긴다.
여기서 생각 할 것은 포인터 라는 것은 다른 데이터 타입과 같이 메모리의 주소값을 코드의 opreand난 레지스터의 direct address mode로 전송하는 과정이 포인터를 처리하는 방식이다.
double dfp;
double *pdfp;
void fun()
{
pdfp = &dfp;
*pdfp = 3.14159265358979323846;
}
void printdouble()
{
printf("&dfp = 0x%08X\n", &dfp );
printf("&pdfp = 0x%08X\n", &pdfp );
printf("pdfp = 0x%08X\n", pdfp );
printf("*pdfp = %1.20lg\n", *pdfp );
printf("*pdfp(hex) = 0x%08X%08X\n", *((unsigned int*)pdfp), *(((unsigned int*)pdfp)+1) );
printf("dfp = %1.20lg\n", dfp );
}
실행 결과 :
&dfp = 0x00403388
&pdfp = 0x00403378
pdfp = 0x00403388
*pdfp = 3.1415926535897931
*pdfp(hex) = 0x54442D18 400921FB : 3.14159265358979323846은 컴파일러에 의해 상수값 0x400921FB54442D18로 바뀌어 취급
dfp = 3.1415926535897931
숫자
3.14159265358979323846 (개발자가 취급하는 숫자) == 0x400921FB54442D18 (컴파일러가 취급하는 숫자-프로그램에 넣은 숫자)
double 은 64비트 숫자 이지만 포인터가 위치를 지정할 때는 무조건 CPU의 주소체계에 의해 x386은 32비트 이다. 그리고 float/double은 32/64비트로 데이터를 움직여야 하기 때문에 x386은 FPU 명령에 의해 이루어 진다.
이번에는 포인터를 활용한 계산하는 방식은
volatile double dfp;
volatile double *pdfp;
void fun()
{
dfp = 3.14159265358979323846;
pdfp = &dfp;
*pdfp *= 180.;
*pdfp /= 2.;
}
; 16 : dfp = 3.14159265358979323846;
00000 dd 05 00 00 00 00 fld QWORD PTR __real@400921fb54442d18
; 17 : pdfp = &dfp;
00006 c7 05 00 00 00 00 00 00 00 00 mov DWORD PTR _pdfp, OFFSET _dfp; pdfp, dfp
00010 dd 1d 00 00 00 00 fstp QWORD PTR _dfp ; dfp
; 18 : *pdfp *= 180.;
00016 dd 05 00 00 00 00 fld QWORD PTR _dfp ; dfp
0001c a1 00 00 00 00 mov eax, DWORD PTR _pdfp ; pdfp
00021 dc 0d 00 00 00 00 fmul QWORD PTR __real@4066800000000000
00027 dd 18 fstp QWORD PTR [eax]
PC 의 x486 이상에서는 FPU가 한 칩내에 있기 때문에 이 명령을 사용하여 동작 한다. IDE(Visual Studio, ...) 툴에 따라 이 옵션을 변경할 수도 있을 것이다. 어째든 default로 컴파일 한다면 FPU를 사용한다.
그렇지만 ARM(ARM7,ARM9,... - Vector Float-Point Processor가 없는 ARM) 처럼 FPU가 없다면 이것은 float-point을 계산하는 함수로 처리 된다.
이번에는 array와 포인터의 관계를 본다.
double dfpData[100];
double *pdfp;
double fun()
{
int cnt;
double ddata;
dfpData[0] = 3.14159265358;
dfpData[1] = 1.0;
dfpData[2] = -100.;
pdfp = dfpData;
}
위 프로그램은 double의 어래이 변수의 예를 보여주는 것인데, 실행결과를 그림으로 표시하면
어래이의 값은
dfpData[0] = 3.14159265358;
dfpData[1] = 1.0;
dfpData[2] = -100.;
이것이 실행되면 어래이 100개 중에 3개의 값이 설정 된다.
참고로 double과 숫자와의 관계는
코드에서 우리가 흔히 사용하는 숫자를 사용하면 컴파일러가 double의 데이터 형태로 바꾼다.
여기서 pdfp가 어래이의 첫번째 주소값을 갖기 위해서는
pdfp = dfpData;
가 실행되면 이제서야 포인터가 위치를 지정 한다.
여기서
pdfp = dfpData;
pdfp = &dfpData[0];
2 줄이 같은 코드이다. C의 모든 포인터에서 변수의 앞 이름만을 사용하면 해당 변수의 초기 변수 위치를 지정 한다.
여기서 만약
pdfp++;
했다면 어떻게 될까?
이것은 모든 포인터의 기본 공식이다.
pdfp = pdfp + 1; => pdfp의 주소값+sizeof(double) = 0x00403388 + 8 = 0x00403390 == &dfpData[1]
다음 데이터가 있는 위치가 된다.
포인터의 증가는 데이터 위치의 증가 이므로 단순히 숫자 1을 더하는 것이 아니다.
double 포인터 표현 몇가지
pdfp = dfpData;
double ddata = *(pdfp+2);
여기서
pdfp+2의 주소 계산은 같은 원리로 인덱스 2가 있는 위치가 된다.
pdfp의 주소값+sizeof(double)*2 = 0x00403388 + 16 = 0x00403398 == &dfpData[2]
와 같이 된다.
이것은 실제로
double ddata = dfpData[2];
와 같은 코드가 된다.
이것을 함수에서 표현을 보면
double sum1(double *pdata, int length)
{
int sum;
for (int cnt =0;cnt < length;cnt++)
sum += *(pdata+cnt);
return sum;
}
double sum2(double *pdata, int length)
{
int sum;
for (int cnt =0;cnt < length;cnt++)
sum += pdata[cnt];
return sum;
}
위의 두 함수 sum1과 sum2는 같은 코드이다.
double sum3(double *pdata, int length)
{
int sum;
for (int cnt =0;cnt < length;cnt++)
sum += *pdata++;
return sum;
}
sum3 만이 다른 포인터 계산 방식으로 코딩 된다.
String과 포인터
C에서 string은 상당히 많이 사용하는 변수이다.
처음 컴퓨터가 시작 후 문자는 몇가지 단계를 거쳐 ASCII로 확정 되었다. 이것은 한 바이트내에 영문자, 기호, 특수 문자 등을 규정 한 것이다. 이 후 컴퓨터가 국제화 되면서 UNICODE가 많이 사용 한다.
한글의 경우 ASCII에 한글 코드 KS-5601으로 완성형으로 표준화 되고, UNICODE와 결합으로 진행 했 왔다. 다양한 코드 형태가 컴퓨터에 사용되어 있어 머리 아프다.
ASCII은 한 바이트 코드인 반면 한글의 KS-5601은 16비트이다. 그리고 UNICODE는 16비트이다.
따라서 이것은 처리에 있어 개발자가 파악을 해야 한다. 그러나 CPU을 프로그램 한다거나, 임베디드에서는 아직도 8비트 ASCII을 많이 사용 한다. 거의 다.
8,16비트 등 다양한 처리가 필요하지만 CPU입장에서 보면 어느 코드가
8비트 엑세스를 할 것인가 16, 32 비트 단위로 억세스 할것인가 만을 처리 한다. 우리가 말하는 문자 코드는 개발자의 약속에
의해 이루어 진다. 더군다나 8비트를 처리하는 char 변수가 문자만을 처리하는 것이 아니고 숫자도 취급하는 하는 변수 이기
때문에 CPU 입장에서는 이것이 문자이지 데이터 인지를 구별 할 필요가 없다.
좀 더 심도있는 내용은
을 참고 하면 된다.
이 글에서 CPU가 엑세스 할 때, 8비트 단위로 할 경우의 예를 설명 하였다.
32/64비트 CPU라도 8,16,32,64 단위로 모두 엑세스가 가능 하여야 한다. 만약 32비트 CPU가 한번에 32비트 단위로만 엑세스 한다면 어떤 문제가 있을까? 다음 예에서 생각 해 본다.
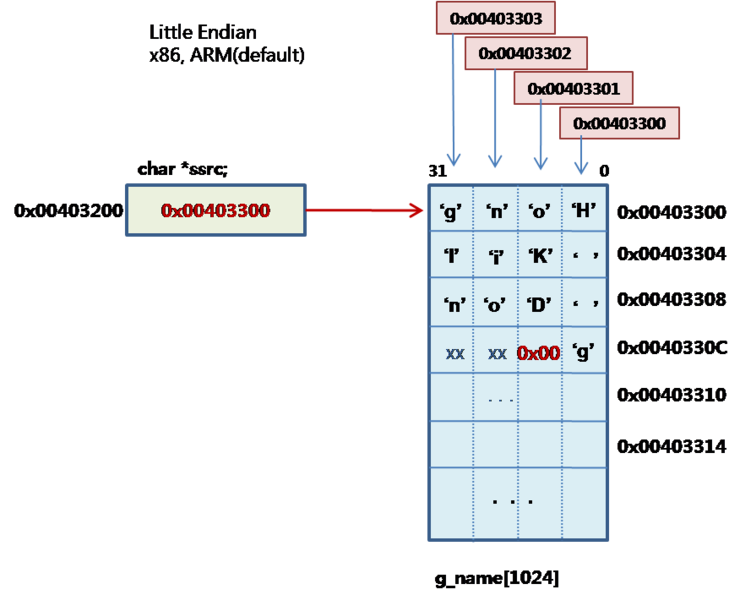
char g_name[1024] = "Hong Kil Dong";
char *strcpy(char *sdest, char *ssrc)
{
char *retstr;
retstr = sdest;
while (*ssrc) {
*sdest++ = *ssrc++;
return retstr;
}
이것은 C 함수에서 흔히 볼수 있는 strcpy 함수 이다. 그런데 string의 내용을 한 바이트 씩 증가하면서 복사 하는 것이다.
여기서
*sdest++ = *ssrc++;
는 한번 씩 주소를 증가하면서 복사해야 하는데
sdest = ssrc;
sdest++;
ssrc++;
ssrc++라는 말은
'현재의 문자에서 다음 문자 위치로 포인터의 주소값을 바꿔라'
라는 의미 이다. 이 말은
현재 포인터 값이 0x00403300 이라면
다음 주소값은 char는 1바이트 이므로 1을 더하면 된다.
ssrc++ : 0x00403300 + sizeof(char) = 0x00403300 +1 = 0x00403301
이 된다.
다음 그림 처럼 메모리의 위치를 배치 할 수 있다.
ssrc++에서 보듯이 다음 주소가 0x00403301이므로 이것으로 부터 값을 읽거나 써야 한다. 이 변수는 읽는거지만.
이렇게 밖에 읽거나 쓸수밖에 없다면 어쩔수 없이 그림 처럼 문자를 배치할 수 밖에 없다. 이 그림에서 낭비되는 메모리를 보았는가? 아...
함수의 예에서 처럼 조작 할 때, 32비트 단위로만 엑세스를 한다면
- 주소 체계는 32비트를 하나의 주소로 증가 하면서 붙인다.
- 만약 8비트 데이터가 필요하여 32비트 엑세스 했다면 나머지 3바이트를 버려야 한다.
- 만약 16비트 데이터라면 2바이트 버린다.
char 변수는 8비트(ASCII의 경우)로 한정된 경우인데, CPU가
32비트 단위로 밖에 엑세스 할 수 없다면 그림처럼 메로리를 배치 하면 된다. strcpy함수 처럼 각각의 바이트를 복사할 경우 한
바이트를 읽어 한 바이트만을 전송 한다. 이런 경우 위의 그림 처럼 배치 된것이 'XX' 부분은 사용을 못하게 된다. 따라서
이것을 버리는 효과가 있다. 스트링 뿐만 아니라 CPU로 데이터를 처리 할 때 일반적인 binary 데이터가 많다. 8비트 뿐만
아니라 16비트 단위의 데이터도 많을 것이다.
그런데 컴퓨터에서 상당히 많이 사용하는데 1바이트를 처리 하기 위해 3바이트 낭비하는 효과가 있다. 이거는 무시 할 수 없는 요소이다.
그 옛날 1999년에서 2000년으로 넘어 갈때, 컴퓨터의 에러가 날것에 대한
공포를 생각해 보면, 여기서의 문제는 년도 표기를 위해 단지 앞의 2자리르 표현하지 않으려는 DATABASE 가 많아서 나타나는
현상이다. 이렇게 메모리의 비율은 중대한 문제이다.
따라서 CPU는 8/16/32/64 단위로 필요에 따라 엑세스 해야 하고, 각각의 엑세스 단위는 CPU의 기계어 명령에 정의 되어 있다.
이것을 해결하기 위해 바이트 단위로 주소값을 부여 한다. 그리고 기계어 코드에 엑세스 단위 명령에 따라 엑세스가 실행 한다.
이 메모리 구조는
각각의 메모리는 바이트 단위로 주소를 부여하고 CPU의 기계어 코드에 따라 CPU가 엑세스를 제어하여 필요한 바이트를 엑세스 한다.
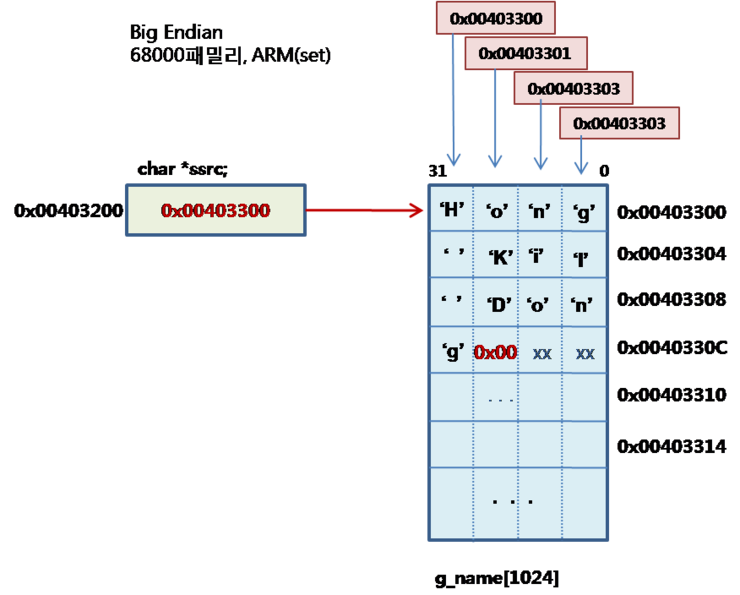
32비트 CPU의 바이트/short의 배치 방식 2가지가 있는데, 이것을
enadian이라고 한다. 32비트 중에서 LSB 쪽 부터 주소를 붙이는 방식을 little endian이라고 하고 꺼구로
32비트의 MSB 부터 번호를 붙이는 방법을 big endain이라고 한다. 다음 그림은 bin endain이다.
잠시 쉬어가지
8비트 부터의 시작된 CPU 메이커는
라이벌이 있었으니, intel과 motolora이다. 그런데 이 두 회사는 16비트/32비트를 만들면서 endian을 반대로
만들었다. intel은 little을 모토롤라는 big을 만들어 우리를 혼동스럽게 한다. 그런데 재미 있는 건, RISC의 대명사
ARM은 둘다 다. 그러나 ARM은 default가 little이다.
초기 PC는 8비트 부터 우리에게 대중화 되었다. 그 전에는 기관의 전산소에 대형 컴퓨터가 있어 이를 사용 하였다. 그런데 PC은 라이벌은 MAC과 IBM PC가 그 주역이다.
MAC : Apple -> MAC : MAX-OS -> OS-X : 6502, 68000패밀리, PowerPC, Intel
IBM : IBM->PC : MS-DOS -->window 3.1 <--> OS2(IBM) -> Window95/98 -> Windows NT, XP, ... : Intel(AMD) x86
80년대 Apple이라는 PC가
만들어져 유행 하였다. 이 때 사용된 CPU가 6502라는 마이크로테크놀로지사에 만들어진 CPU이다. 한국에는 한참
Apple-II가 유행 하였다. 급히 IBM에서는 급조된 PC을 만들에 되었는데, 바로 IBM-PC 소프트웨어는 마이크로소프트사의
MS-DOS가 주역이다. 대중화를 통한 본격적인 라이벌의 경쟁이 시작 된 것이다. IBM은 이 과정에서 HW의 회로를 모두
공개하고 개작과 함께 대만의 PC의 메인보드 개발과 상업화의 불씨가 되었다. 소프트웨어 입자에서는 MS 라는 호랑이를 키우고
말았다. MS의 MS-DOS의 근본(전신)은 CP/M이다. 이를 개작(?) 했다고 말할 수 있을 것이다. CP/M을 만든 개발자가
IBM과의 연결이 실패하여 빌게이츠가 나타난 것이다.
이렇게 Apple은 MAC으로 진화하고
IBM PC는 경쟁사로 대립 하면서. 그런데 apple은 MAC을 진화 시키면서 모토롤라의 68000계열로 넘어가고 다시
90년대에 PowerPC(IBM CPU)을 채택하여 진화 하였다. 이 때 바로 68000계열을 포기하면서 모토롤라에게
68000패밀리의 포기하는 단초를 만들었다. 더군다나 초기의 workstation도 선사에서 이미 포기하고 다른 CPU을 사용하고
있었다. 결국 68000패밀리는 역사속으로... 현재 모토롤라는 PowerPC에 기초한 임베디드 CPU가 살아남았다.빵빵한
네트웨크 응용 장비에 많이 사용하였다. 이에 비해 intel의 CPU는 AMD와 또 다른 CPU 경쟁을 하면서 우위를 지키고 있어
견실하다. 이에 비해 MAC 진형에서는 IBM의 PowerPC에 기반 둔 진화를 포기할 수 밖에 없는 상황으로 몰리고 있다.
IBM은 intel 처럼 CPU 전문회가사 아니므로 적극적으로 시장에 대처하지 못해 MAC OS을 뒤바침하지 못하고 있다. 결국
MAC 경영진은 intel의 CPU 채택을 선언한 상황이다. 그리고 OS는 Unix에 기반한 MAC OS-X로 진화 하고 있다.
90년대 MAC의 오피스 프로그램은 IBM-PC의 그것과 차원이 다른 소프트웨어 였다. 그러나 현재 윈도우의 오피스에 밀리고 MAC 회사 자체가 MS사에 넘어가서 자회사가 되었으니, 참으로 영원한 강자는 없는 듯...
그런데 MS사는 영원 할것인가? 누가 라이벌로 나타날 것인까? 이 아성을 깨는 과정은 독과점 체제 때문에 다른 소프트웨어 체제가 나타나서 기존의 윈도우를 무너 뜨리는 방법이 가장 추측 가능한 미래이다.
그렇다면 새로운 소프트웨어 체계 란????????????????????????????????????????????
그렇다면 UNICODE 라면
UNICODE을 Visual C++에서 정의하는 방법은
단, Visual Studio C++ 6.0에서 이다. 디폴트는 MBCS이다.
그러나 Visual Sudio C++2005/2008에서는 tchar_t가 defalut UNICODE이다. 따라서 상당부분의
기존 C함수에서 문자 코드가 문제가 된다.
다음은 Visual Studio C++ 6.0을 기준으로 설명 한다.
#define UNICODE --> 이렇게 하거나 툴에서 define을 추가하는 항목에 이 정의값을 넣으면 된다.
tchar_t *g_name = _T("Hong Kil Dong");
tchar_t *ssrc;
ssrc = g_name;
TCHAR <== tchar_t로 선언
이 프로그램의 실행하기 위한 메모리 배치 구조가 위의 그림이다. wchar_t 사용 시, 만약 _UNICODE을 선언하지 않고 _MBCS가 선언되면 UNICODE가 만들어 지지 않는다. 이것은 결국 기존의 8비트 char로 처리 된다.
#define에 상관없이 UNICODE로 처리 하려면 다음과 같이 wchar_t을 사용 한다. 이것은 16비트 UNICODE가 된다.
wchar_t *g_name = L"Hong Kil Dong";
wchar_t *ssrc;
ssrc = g_name;
WCHAR <== wchar_t로 선언
만약 위의 프로그램에 다음을 연결한다면
char *pstr;
pstr = (char*) g_name:
printf(pstr);
결과 : H
땅랑 "H" 만 출력 된다. UNICODE가 16비트의 코드를 만들 때, 영문자는 상위 8비트를 0으로 채웠다. 따라서 이것을 단순히 char*로 타입변환한다면
'H' 0x0 'o' 0x0 'n' ...
이렇게 나열된다. 따라서 'H' 다음의 0이 스트링 종료로 인식되어 글자 H 만 출력 된다.
결국
wchar_t === unsigned short int ---> 16비트 처리 단위 지정
와 다를 것이 없다.
단, 이것은 우리가 사용하는 x386이다.
big-endian에서는
0x0 'H' 0x0 'o' ...
이렇게 되면 아마도 어떤 글자도 없는 상황이 될것으로 추측 한다. 개인적으로 PC중에 big-endian은 사용해 보지 않어서리...
그러면 포인터가 어떻게 동작 하는가?
char *strcpy(char *sdest, char *ssrc)
{
char *pstr;
pstr = sdest;
{
char *pstr;
pstr = sdest;
*pstr = 0;
while (*ssrc)
*pstr++ = *ssrc++;
*pstr++ = *ssrc++;
*pstr = 0;
return sdest;
}
}
중요한 코드 몇 개만 확인하면
_TEXT SEGMENT
_pstr$ = -8 ; size = 4
_sdest$ = 8 ; size = 4
_ssrc$ = 12 ; size = 4
_pstr$ = -8 ; size = 4
_sdest$ = 8 ; size = 4
_ssrc$ = 12 ; size = 4
_strcpy PROC ; strcpy, COMDAT
; 9 : {
00000 55 push ebp
00001 8b ec mov ebp, esp
; 9 : {
00000 55 push ebp
00001 8b ec mov ebp, esp
. . .
; 12 : pstr = sdest;
0001e 8b 4508 mov eax, DWORD PTR _sdest$[ebp] --> ebp가 넘겨받은 인수의 stack의 변수 위치이다.
00021 89 45f8 mov DWORD PTR _pstr$[ebp], eax --> pstr에 sdest에서 받은 포인터의 주소값을 넣는다.
0001e 8b 4508 mov eax, DWORD PTR _sdest$[ebp] --> ebp가 넘겨받은 인수의 stack의 변수 위치이다.
00021 89 45f8 mov DWORD PTR _pstr$[ebp], eax --> pstr에 sdest에서 받은 포인터의 주소값을 넣는다.
; 13 : *pstr = 0;
00024 8b 45f8 mov eax, DWORD PTR _pstr$[ebp] ---> pstr의 포인터 주소값을 EAX레지스터로 옮긴다.
00027 c6 0000 mov BYTE PTR[eax], 0 ---> EAX가 지정하는 주소에 0을 넣는다. 이 때 전송할 데이터는 char 타입으로 1바이트 데이터 이다.
00024 8b 45f8 mov eax, DWORD PTR _pstr$[ebp] ---> pstr의 포인터 주소값을 EAX레지스터로 옮긴다.
00027 c6 0000 mov BYTE PTR[eax], 0 ---> EAX가 지정하는 주소에 0을 넣는다. 이 때 전송할 데이터는 char 타입으로 1바이트 데이터 이다.
*pstr++ = *ssrc++;
이 코드를 처리하는 과정은
1. *pstr = *ssrc;
*pstr -> EAX
*ssrc => ECX
00034 8b 45 f8 mov eax, DWORD PTR _pstr$[ebp]
00037 8b 4d 0c mov ecx, DWORD PTR _ssrc$[ebp]
00037 8b 4d 0c mov ecx, DWORD PTR _ssrc$[ebp]
DL로 데이터 옮기고
0003a 8a 11 mov dl, BYTE PTR[ecx]
DL 데이터를 다시 EAX(pstr의 주소값)가 지정하는 주소에 복사
0003c 88 10 mov BYTE PTR[eax], dl
2. pstr++ 실행 과정
0003e 8b 45f8 mov eax, DWORD PTR _pstr$[ebp] --> 현재의 pstr에 있는 포인터 주소값을 읽어 EAX 레지스터에 넣는다.
00041 83 c0 01 add eax, 1 --> 다음 문자로 옮기기 위해 주소값을 sizeof(char)=1 만큼 증가한다.
00041 83 c0 01 add eax, 1 --> 다음 문자로 옮기기 위해 주소값을 sizeof(char)=1 만큼 증가한다.
00044 89 45f8 mov DWORD PTR _pstr$[ebp], eax --> 증가 된 주소값을 pstr 변수에 넣는다.
3. ssrc++ 실행 과정
00047 8b 4d 0c mov ecx, DWORD PTR _ssrc$[ebp]
0004a 83 c1 01 add ecx, 1
0004a 83 c1 01 add ecx, 1
0004d 89 4d 0c mov DWORD PTR _ssrc$[ebp], ecx
위의 실행 구조를 알기 위해 프로그램을 약간 수정
char g_name[1024] = "Hong Kil Dong";
char dname[1024];
char *strcpy(char *sdest, char *ssrc)
{
char *pstr;
pstr = sdest;
printf("&ssrc = 0x%08X\n", (unsigned int ) &ssrc);
printf("&sdest = 0x%08X\n", (unsigned int ) &sdest);
printf("&pstr = 0x%08X\n", (unsigned int ) &pstr);
printf("ssrc = 0x%08X\n", (unsigned int ) ssrc);
printf("sdest = 0x%08X\n", (unsigned int )sdest);
printf("pstr = 0x%08X\n", (unsigned int ) pstr);
char dname[1024];
char *strcpy(char *sdest, char *ssrc)
{
char *pstr;
pstr = sdest;
printf("&ssrc = 0x%08X\n", (unsigned int ) &ssrc);
printf("&sdest = 0x%08X\n", (unsigned int ) &sdest);
printf("&pstr = 0x%08X\n", (unsigned int ) &pstr);
printf("ssrc = 0x%08X\n", (unsigned int ) ssrc);
printf("sdest = 0x%08X\n", (unsigned int )sdest);
printf("pstr = 0x%08X\n", (unsigned int ) pstr);
while (*ssrc)
*pstr++ = *ssrc++;
*pstr = 0;
return sdest;
}
return sdest;
}
int main(int argc, char* argv[])
{
char *pstr = strcpy(dname, g_name);
printf("strcpy = [%s]\n", pstr);
{
char *pstr = strcpy(dname, g_name);
printf("strcpy = [%s]\n", pstr);
}
실행 결과 :
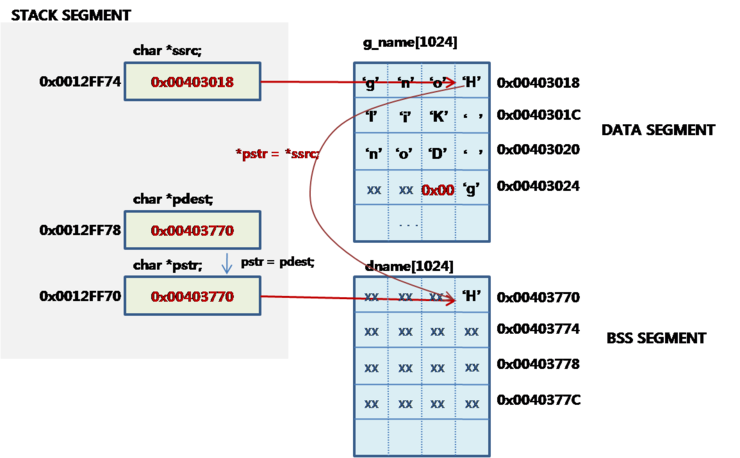
&ssrc = 0x0012FF74
&sdest = 0x0012FF78
&pstr = 0x0012FF70
ssrc = 0x00403018
sdest = 0x00403770
pstr = 0x00403770
strcpy = [Hong Kil Dong]
&sdest = 0x0012FF78
&pstr = 0x0012FF70
ssrc = 0x00403018
sdest = 0x00403770
pstr = 0x00403770
strcpy = [Hong Kil Dong]
위의 변수 구조를 그리면
보통 함수로 인수 전달하면 인수 변수와 내부 지역변수의 숫자가 작은면 레지스터에 변수를 할당하여 실행 한다. 그러나 변수수가 많으면 내부의 변수는 stack을 사용 할 수 있다.
위 함수에서 변수 ssrc, sdest, pstr은 모든 stack에 할당 되었다.
포인터 이야기는 다음 글에서 계속 된다.
댓글 없음:
댓글 쓰기